Once I decided to stop chasing the startup path and go back into the job market, I ran into a very practical problem.
There were plenty of roles on paper, but not that many companies I genuinely wanted to spend serious time on. You can open vacancies one by one, read the JD, look up the company, inspect the product, compare the market position, and do all the sensible things. The trouble is that, after a while, you realise you are spending an absurd amount of time on screening out what is not worth deeper research.
So the tool I wanted was not a machine for spraying applications everywhere. I wanted something that could help me shrink the search space quickly, so I could save my attention for the handful of roles that actually deserved it.
More specifically, I wanted a workflow that I could talk to through LINE in normal human language:
- fetch recent product manager roles
- only show me the ones above 80
- what about the second one
- analyse this one for me
The difficult bit is not the scraper. It is not even the API plumbing. The real difficulty is that users do not speak like workflow designers. If the system treats every message as a fresh webhook event, it may look automated, but it does not feel like a proper tool.
That is why I split this write-up into two parts.
- Part 1 focuses on the front half: LINE intake, semantic parsing, orchestration, routing, and recent-job scraping.
- Part 2 moves into the heavier back half: fast scoring, deeper RAG-style analysis, and structured error handling.
If you are new to the series, start here. All the attractive capabilities in the second half depend on something more basic: whether the system can first work out what the current message is actually referring to.

To be precise, this is not a fully autonomous agent
I deliberately call this a job agent, but if I wanted to be stricter about the terminology, it is closer to a workflow with agent-like behaviour.
A lot of the execution paths are still predefined. This is not the sort of fully autonomous setup where the model dynamically decides the entire tool loop from scratch. It is better described as a Make workflow that has grown three capabilities that ordinary single-turn automations are often missing:
- it reads prior context;
- it asks for clarification when the target is unclear;
- it stores the previous turn in a form the next turn can genuinely reuse.
That boundary matters. It keeps the article from collapsing into another lazy habit in AI writing, where anything with an LLM attached gets called an agent.
The real workload I was trying to solve
What I was solving was not “how to build a chatbot in Make”. It was a more concrete workload than that:
I wanted a chat-first system that could help me narrow down which roles were worth deeper research before I spent hours on them.
That workload has three important properties:
- the user input is short and often incomplete;
- many follow-ups depend on the previous result, such as “the second one” or “analyse that”;
- the valuable part is not merely fetching data, but ranking attention before expensive analysis happens.
That is why Part 1 is not about collecting more data. It is about building a front half that is trustworthy enough for the back half to lean on.
A stable naming scheme for the whole series
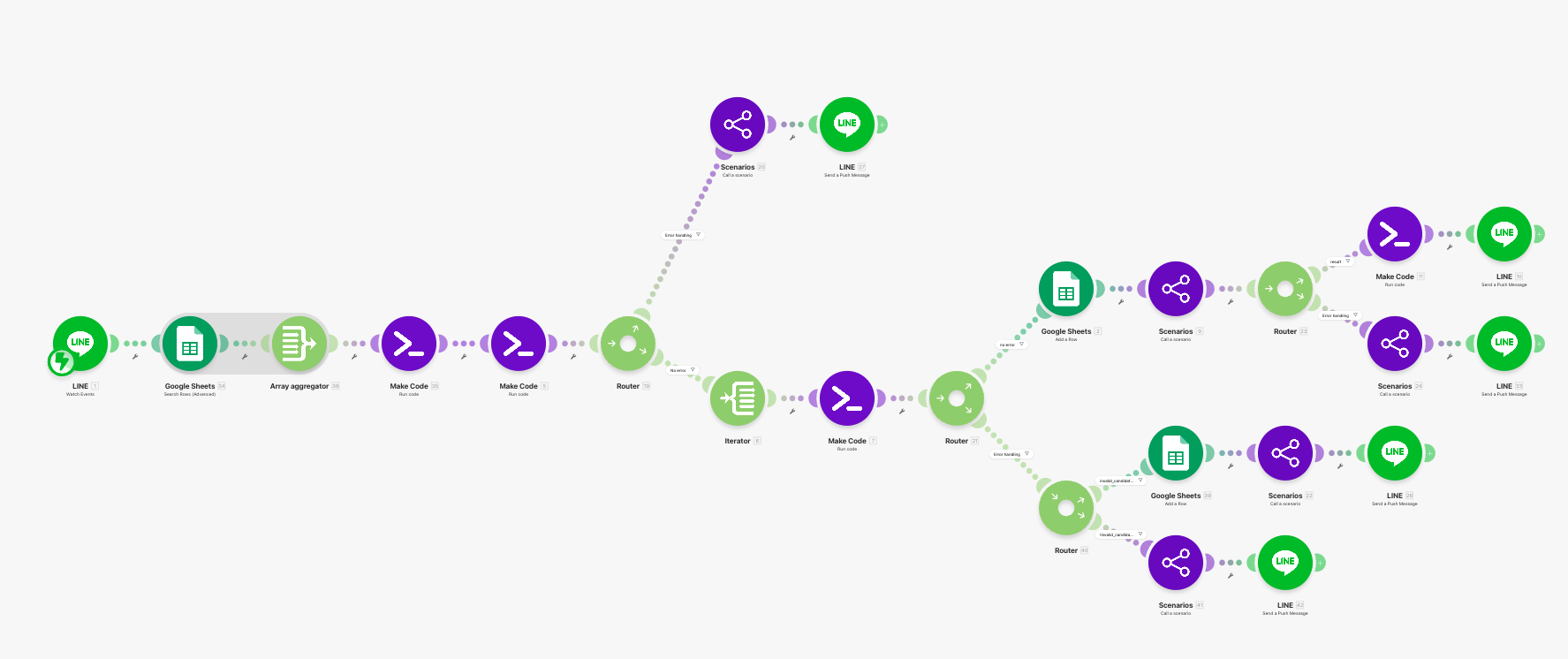
Instead of using the original Make module IDs, I renamed the system components in reading order. That makes the two-part series feel like one coherent architecture rather than a trail of arbitrary numbers.
Part 1 uses JA-01 to JA-21. Part 2 will continue from JA-22, so the naming stays stable across both posts.
Part 1 component map
| ID | Component name | Purpose |
|---|---|---|
| JA-01 | LINE Webhook Gateway | Receives raw messages, reply tokens, and user IDs from LINE. |
| JA-02 | Recent Task Lookup | Reads recent usable rows from agent_tasks for the same user. |
| JA-03 | History Context Builder | Compresses recent state into structured history_context. |
| JA-04 | Deterministic Semantic Parser | Splits short chat messages and extracts actionable entities. |
| JA-05 | Continuation Resolver | Decides whether the message starts fresh, continues a list, continues a single job, or needs clarification. |
| JA-06 | Task Record Builder | Produces the durable task_record that the router can execute. |
| JA-07 | Clarification Composer | Builds structured clarification state and the follow-up prompt. |
| JA-08 | Task Queue Writer | Writes new tasks back into agent_tasks. |
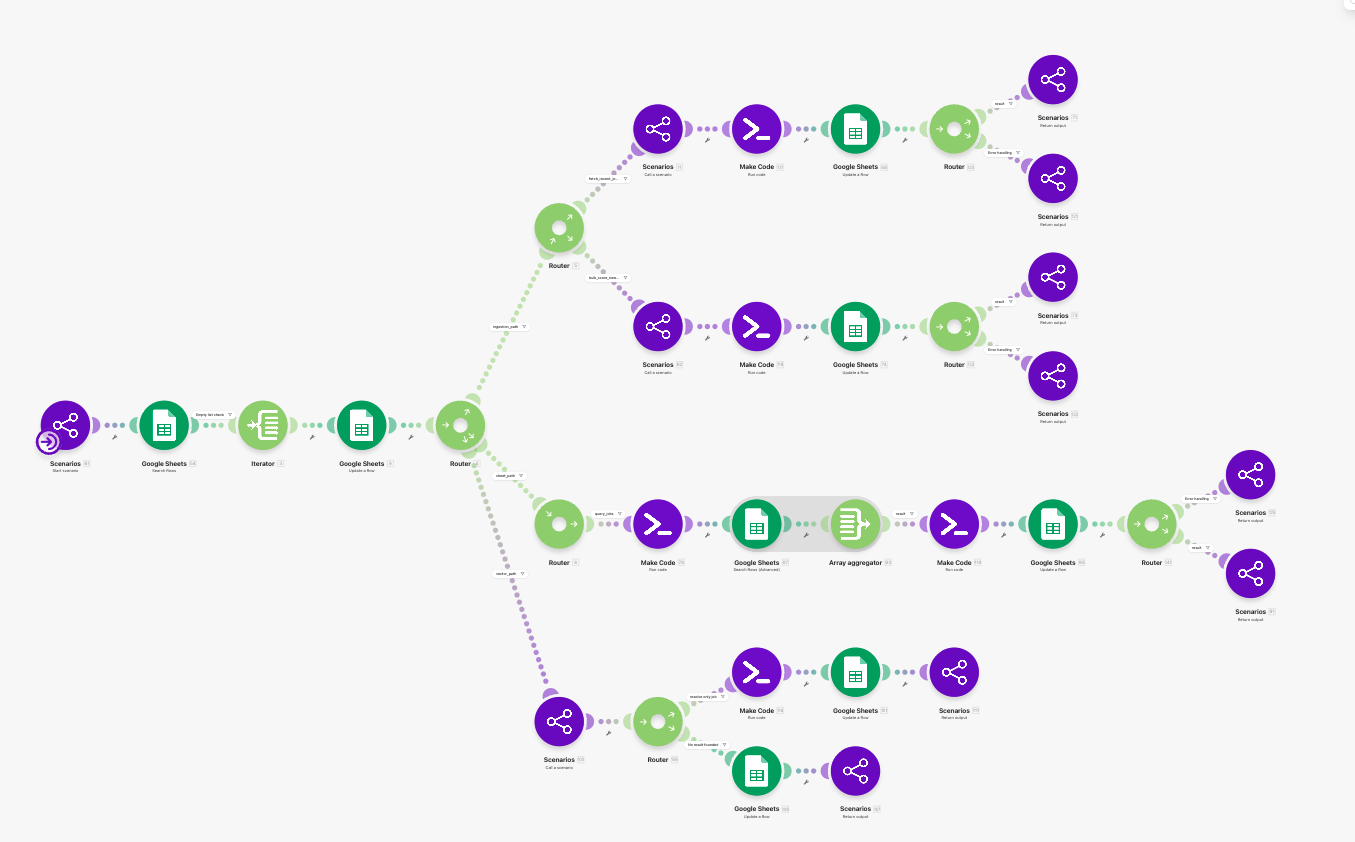
| JA-09 | Queue Loader | Pulls ready tasks out of agent_tasks. |
| JA-10 | Task Locker | Locks a task before execution. |
| JA-11 | Route Selector | Sends the task into the appropriate execution lane. |
| JA-12 | Query Spec Builder | Turns conversational filters into a structured query against jobs_raw. |
| JA-13 | Query Result Formatter | Formats shortlist results for both human reply and future reuse. |
| JA-14 | Scraping Lane Launcher | Starts the recent-job ingestion lane. |
| JA-15 | URL Queue Builder | Normalises role keywords and produces JobStreet search URLs. |
| JA-16 | Existing Job-ID Snapshot | Reads current job IDs from jobs_raw for deduplication. |
| JA-17 | Page Fetcher | Uses Zyte to fetch each search-results page. |
| JA-18 | HTML Extractor & Role Filter | Parses job cards and removes clearly irrelevant roles. |
| JA-19 | Deduplicator & Sheet Writer | Inserts only genuinely new rows into jobs_raw. |
| JA-20 | Reply Composer | Converts results into LINE-friendly human text. |
| JA-21 | LINE Messenger | Sends the final message back to LINE. |
Why I deliberately did not use an LLM for the first parser
This is probably the easiest part of the design to misunderstand.
The first instinct many people have is: if the system starts in chat, why not let an LLM own the semantic parsing layer from the beginning?
My answer is not that LLMs are bad. It is that this stage needs control more than style.
The intake layer is not there to produce elegant prose. It is there to transform a short message into a stable execution state. At minimum, it needs to do things like these:
- recognise that
4may mean “the fourth result”; - recognise that
90680721may be answering the previous clarification rather than starting a brand-new search; - recognise that “analyse that” is missing a target job, not a task type;
- recognise that “fetch recent PM roles, then only show the ones above 80” is actually a multi-step intent.
Once that stage gets the reference wrong, the rest of the pipeline can be brilliant and still fail. The system has already hung the task on the wrong hook.
A deterministic parser has a very practical advantage here: you know why it made the decision it made.
If it fails to treat a bare number as an ordinal selection, you can patch the branch.
If it gives old context more weight than an explicit job ID, you can change the precedence.
If it misroutes a follow-up into query_jobs, you can trace the mistake through history_context step by step.
That led me to a working rule I trust quite a lot:
The closer you are to the system entrance, the more you should optimise for reproducibility, observability, and patchability.
The model is not banished. It is simply more valuable later, when the job becomes one of judgement, synthesis, and explanation rather than reference resolution.

agent_tasks is not just a queue
If you think of agent_tasks as nothing more than a task table, the architecture does not really make sense.
In this system it has two jobs at once:
- it is a task queue;
- it is also the memory source for the next turn.
Once those two roles sit on top of each other, the design question changes. It is no longer just “how do I store the last result?” It becomes:
what exactly does the next turn need to carry forward from the previous one?
My answer was not a full transcript, and certainly not every field under the sun. What the next turn actually needs is structured information that can support reference resolution, such as:
- whether the previous result was a list or a single reference;
- which
job_idswere in play; - which one was the
primary_job_id; - which task type the next step most likely expects;
- whether there is still an open clarification waiting for an answer.
That is why JA-03 is not really “chat history compression”. It is better described as a carry-forward context builder.
Intake is really about reference resolution, not just intent classification
This was the biggest design shift for me.
At first glance, it feels as though the main challenge should be intent classification. Once you place the workflow inside a real chat interface, however, a different problem becomes much more common:
analyse that for me
The task type is not actually the hard bit. The hard bit is: which job are you referring to?
So JA-04 to JA-07 are not merely trying to label the message as query_jobs, analyze_job, or generate_application_pack. They are first asking questions like these:
- does this message contain an explicit job ID;
- is it answering the previous clarification;
- is it selecting one item from the previous list;
- is it continuing a single-job context from the last turn;
- if the target is still unclear, should the system clarify rather than fail.
That is also why I stopped thinking of clarification as error handling. If the system knows the action but not the target entity, that is not a generic failure. It is a missing reference, and the product should respond accordingly.
The router should stay in its lane
Once JA-06 has produced a proper task_record, the router becomes much cleaner.
At that point its job should simply be: how do I execute this?
Not:
- should I reinterpret this as a continuation;
- should I guess the target job one more time;
- should I silently recast this into some other task type.
I kept those decisions in the intake layer on purpose. If the router also starts second-guessing the meaning of the message, bugs become slippery. You think the message was resolved upstream, and then a lane quietly turns it back into something else.
In Part 1, JA-11 mainly sends tasks into two lanes that I unpack in this post:
- Sheet Query Lane for browsing roles already saved in
jobs_raw; - Ingestion Lane for fetching newer roles from external sources.
There is also a heavier Vector / RAG Lane, but that belongs to Part 2.

The sheet-query lane solves a very specific problem
When people hear “job agent”, they often jump straight to the scraper. In practice, the local shortlist experience matters just as much.
JA-12 does something quietly useful: it translates conversational filters into a structured query against jobs_raw. That includes things like:
- recency window;
- score threshold;
- keyword buckets;
- top-k selection;
- sort field and sort order.
JA-13 then sorts and formats the results while doing two different jobs at once:
- producing human-readable reply text;
- producing compact reusable memory for the next turn.
That dual output matters. The best shape for a reply and the best shape for future machine reuse are rarely the same document.
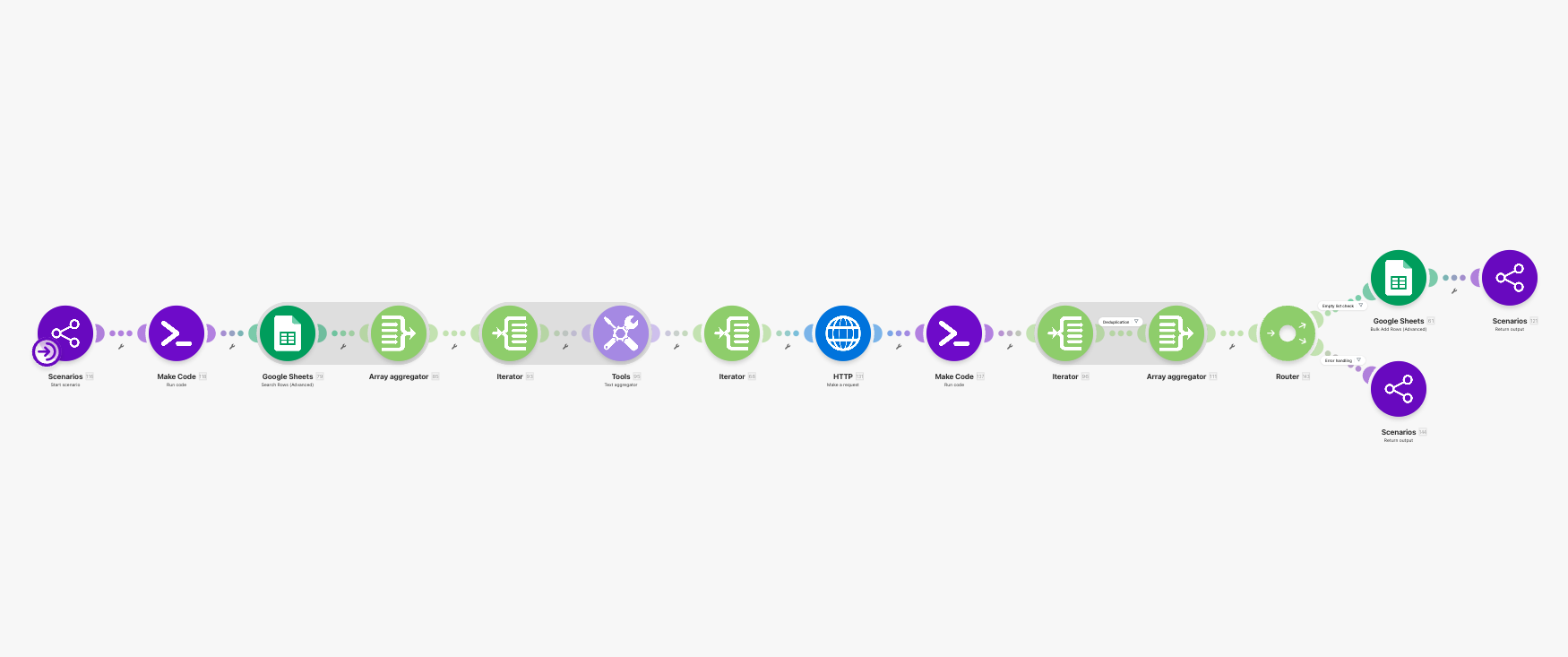
The ingestion lane is where this becomes a real job-search tool
If intake solves the “carry-forward” problem, the ingestion lane solves the “do not waste my time” problem.
Its goal is not to scrape as much as possible. Its goal is to bring recent jobs into the system in a form that is maintainable, deduplicated, and ready for later scoring.
I split that lane into a set of article-friendly components:
-
JA-15 URL Queue Builder
Normalises the role keyword, applies sensible defaults fordaysandpage_from/page_to, and emits fetch-ready search URLs. -
JA-16 Existing Job-ID Snapshot
Reads the currentjobs_rawIDs before any fetch happens, so deduplication becomes an explicit step rather than an afterthought. -
JA-17 Page Fetcher
Uses Zyte to retrieve each search-results page. This is a deliberately practical choice: the goal is stable page retrieval, not elaborate browser theatre. -
JA-18 HTML Extractor & Role Filter
Pulls job cards out of the HTML and drops obviously noisy roles before they ever reach storage, such as entry-level positions or heavily sales/marketing-adjacent jobs. -
JA-19 Deduplicator & Sheet Writer
Inserts only genuinely new rows intojobs_rawrather than filling the sheet with duplicates every time the search runs.
That is why I do not think of this lane as “just the scraper”. It is already a front-end screening layer. It pushes obvious noise away before the more expensive judgement in Part 2 ever starts.

An important counterexample: not every job workflow needs this much structure
This architecture is not a universal answer.
If your requirement is simply:
- scrape once a day on a schedule;
- no chat-style follow-ups;
- users always provide complete structured inputs;
- no need to remember short-lived context between turns,
then this design is probably too heavy.
In that situation, you may not need history context, a clarification state, or a table that acts as both queue and memory source. Those choices only start to pay off when users really do speak in short follow-ups that depend on the previous turn.
So the main claim in this article has an explicit precondition:
this approach is most useful when the front door is genuinely conversational, not just a scheduled ingestion workflow or a form.
Without that precondition, the simpler system is often the better one.
The judgement I most want to leave behind
If I had to compress Part 1 into one line, it would be this:
Giving a Make workflow carry-forward behaviour is not mainly about adding more LLM. It is about getting context, reference resolution, routing, and ingestion right first.
That sequence matters.
If intake is wrong, scoring later will score the wrong job.
If routing is messy, the wrong lane will run.
If ingestion is noisy, the expensive analysis that follows is just high-cost noise processing.
Part 2 will pick up from there and move into the sections where model judgement genuinely earns its keep:
- fast scoring for new roles;
- deeper RAG-style analysis of a selected job;
- error handling as a structured product capability rather than a generic fallback.
But if you ever read Part 2 first and trace the system backwards, you usually end up at the same conclusion anyway:
how deep you can go later depends on how stable the front half already is.